Feature selection can greatly improve your machine learning models. In this series of blog posts, we will discuss all you need to know about feature selection.
- We start with explaining why feature selection is important – even in the age of deep learning. We then move on and establish that feature selection is actually a very hard problem to solve. We will cover different approaches which used today but have their own problems. This concludes the first blog post.
- We will then explain why evolutionary algorithms are one of the best solutions. We will discuss how they work and why they perform well even for large feature subsets.
- In the third post, we will improve the proposed technique. We will simultaneously improve the accuracy of models and reduce their complexity. This is the holy grail of feature selection. The proposed method should become your new standard technique.
- We will end with a discussion about feature selection for unsupervised learning. It turns out that you can use the multi-objective approach even in this case. Many consider feature selection for clustering to be an unsolved problem. But by using the proposed technique you can get better clustering results as well!
Ok, so let’s get started by defining the basics of feature selection first.
Why should we care about Feature Selection?
There is consensus that feature engineering often has bigger impact on the quality of a model than the model type or its parameters. And feature selection is a key part of feature engineering. Also, Kernel functions and hidden layers are performing implicit feature space transformations. So, is feature selection then still relevant in the age of SVMs and Deep Learning? The answer is: Yes, absolutely!
First, you can fool even the most complex model types. If there is enough noise overshadowing the true patterns, it will be hard to find them. The model starts to model the noise patterns of the unnecessary features in those cases. And that means, that it does not perform well at all. Or, even worse, it starts to overfit to those noise patterns and will fail on new data points. It turns out that it even easier to fall into this trap for high number of data dimensions. And no model type is better than others in this regard. Decision trees can fall into this trap as well as multi-layer neural networks. Removing noisy feature can help the model to focus on the relevant patterns instead.
But there are two more advantages of feature selection. If you reduce the number of features, models are generally trained much faster. And the resulting model often is simpler which makes it easier to understand. And more importantly, simpler models tend to be more robust. This means that they will perform better on new data points.
To summarize, you should always try to make the work easier for your model. Focus on the features which carry the signal over those which are noise. You can expect more accurate models and train them faster. Finally, they are easier to understand and are more robust. Sweet.
Why is this a hard problem?
Let’s begin with an example. We have a data set with 10 attributes (features, variables, columns…) and one label (target, class…). The label column is the one we want to predict. We trained a model on this data and evaluated it. The accuracy of the model built on the complete data was 62%. Is there any subset of those 10 attributes where a trained model would be more accurate than that? This is exactly the question feature selection tries to answer.
We can depict any attribute subset of 10 attributes as bit vectors, i.e. as a vector of 10 binary numbers 0 or 1. A 0 means that the specific attribute is not used while a 1 depicts an attribute which used for this subset. If we, for example, want to indicate that we use all 10 attributes, we would use the vector (1 1 1 1 1 1 1 1 1 1). Feature selection is the search for such a bit vector leading to a model with optimal accuracy. One possible approach for this would be to try out all the possible combinations. We could go through them one by one and evaluate how accurate a model would be using only those subsets. Let’s start with using only a single attribute then. The first bit vector looks like this:
 As you can see, we only use the first attribute and a model only built on this subset has an accuracy of 68%. That is already better than what we got for all attributes which was 62%. But maybe we can improve even more? Let’s try using only the second attribute now:
As you can see, we only use the first attribute and a model only built on this subset has an accuracy of 68%. That is already better than what we got for all attributes which was 62%. But maybe we can improve even more? Let’s try using only the second attribute now:
 Still better than using all 10 attributes but not as good as only using the first. But let’s keep trying:
Still better than using all 10 attributes but not as good as only using the first. But let’s keep trying:
 We keep going through all possible subsets of size 1 and collect all accuracy values. But why we should stop there? We should also try out subsets of 2 attributes now:
We keep going through all possible subsets of size 1 and collect all accuracy values. But why we should stop there? We should also try out subsets of 2 attributes now:
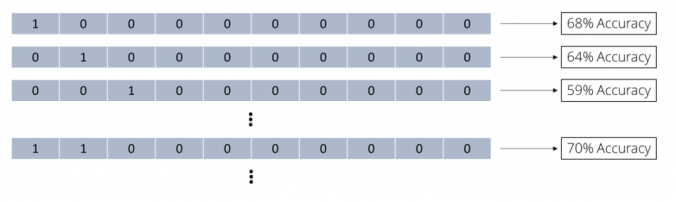 Using the first two attributes immediately looked promising with 70% accuracy. We keep going through all possible subsets of all possible sizes. We collect all accuracy values of those subsets until we tried all possible combinations:
Using the first two attributes immediately looked promising with 70% accuracy. We keep going through all possible subsets of all possible sizes. We collect all accuracy values of those subsets until we tried all possible combinations:
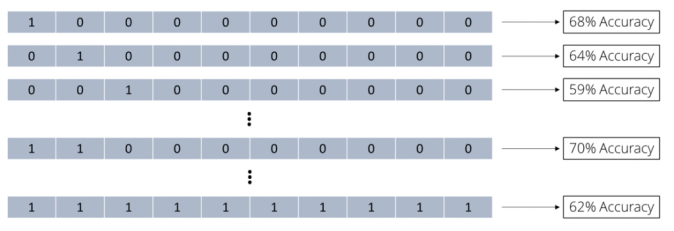 We now have the full picture and can use the best subset out of all these combinations. Because we tried all combinations, we also call this a brute force approach.
We now have the full picture and can use the best subset out of all these combinations. Because we tried all combinations, we also call this a brute force approach.
How many combinations did we try for our data set consisting of 10 attributes? We have two options for each attribute: we can decide to either use it or not. And we can make this decision for all 10 attributes which results in 2 x 2 x 2 x … = 210 or 1024 different outcomes. One of those combinations does not make any sense though, namely the one which does not use any features at all. So, this means that we only would try 210 – 1 = 1023 subsets. Anyway, even for a small data set with only 10 attributes this is already a lot of attribute subsets we need to try. Also keep in mind that we perform a model validation for every single one of those combinations. If we used a 10-fold cross-validation, we now trained 10230 models already. That is a lot. But it is still doable for fast model types on fast machines.
But what about more realistic data sets? This is where the trouble begins. If we have 100 instead of only 10 attributes in our data set, we already have 2100 – 1 combinations. This brings the total number of combinations already to 1,267,650,600,228,229,401,496,703,205,375. Even the biggest computers can no longer do this. This rules out such a brute force approach for any data set consisting of more than just a handful features.
Heuristics to the Rescue!
Going through all possible attribute subsets is not a feasible approach then. But what can we do instead? We could try to focus only on such combinations which are more likely to lead to more accurate models. We try to prune the search space and ignore feature sets which are not likely to produce good models. However, there is of course no guarantee that you will find the optimal solution any longer. If you ignore complete areas of your solution space, it might be that you also skip the optimal solution. But at least such heuristics are much faster than the brute force approach. And often you will end up with a good and sometimes even with the optimal solution in a much faster time.
There are two widely used approaches for feature selection heuristics in machine learning. We call them forward selection and backward elimination. The heuristic behind forward selection is very simple. you first try out all subsets with only one attribute and keep the best solution. But instead of trying all possible subsets with two features next, you only try specific 2-subsets. You only try those 2-subsets which contain the best attribute from the previous round. If you do not improve, you stop and deliver the best result from before, i.e. the single attribute. But if you have improved the accuracy, you keep trying by keeping the best attributes so far and try to add one more. You keep doing this until you no longer improve.
What does this mean for the runtime for our example with 10 attributes from above? We start with the 10 subsets of only one attribute which is 10 model evaluations. We then keep the best performing attribute and try the 9 possible combinations with the other attributes. This is another 9 model evaluations then. We stop if there is no improvement or keep the best 2-subset if we got a better accuracy. We now try the 8 possible 3-subsets and so on. So, instead of going brute force through all 1023 possible subsets, we only go through 10 + 9 + … + 1 = 55 subsets. And we often will stop much earlier as soon as there is no further improvement. We will see below that this is often the case. This is an impressive reduction in runtime. And the difference becomes even more obvious for the case with 100 attributes. Here we will only try at most 5,050 combinations instead of the 1,267,650,600,228,229,401,496,703,205,375 possible ones.
Things are similar with backward elimination, we just turn the direction around. We begin with the subset consisting of all attributes first. Then, we try to leave out one single attribute at a time. If we improved, we keep going. But we still leave out the attribute which led to the biggest improvement in accuracy. We then go through all possible combinations by leaving out one more attribute. This is in addition to the best ones we left already out before. We continue doing this until we no longer improve. Again, for 10 attributes this means that we will have at most 1 + 10 + 9 + 8 + … + 2 = 55 combinations we need to evaluate.
Are we done then? It looks like we found some heuristics which work much faster than the brute force approach. And in certain cases, these approaches will deliver a very good attribute subset. The problem is that in most cases, they unfortunately will not. For most data sets, the model accuracy values form a so-called multi-modal fitness landscape. This means that besides one global optimum there are several local optima as well. Both methods will start somewhere on this fitness landscape and will move from there. In the image below, we marked such a starting point with a red dot. From there, they will continue to add (or remove) attributes if the fitness improves. They will always climb up the nearest hill in the multi-modal fitness landscape. And if this hill is a local optimum they will get stuck in there since there is no further climbing possible. Hence, those algorithms do not even bother with looking out for higher hills. They take whatever they can easily get. Which is exactly why we call those algorithms “greedy” by the way. And when they stop improving, there is only a very small likelihood that they made it on top of the highest hill. It is much more likely that they missed the global optimum we are looking for. Which means that the delivered feature subset is often a sub-optimal result.
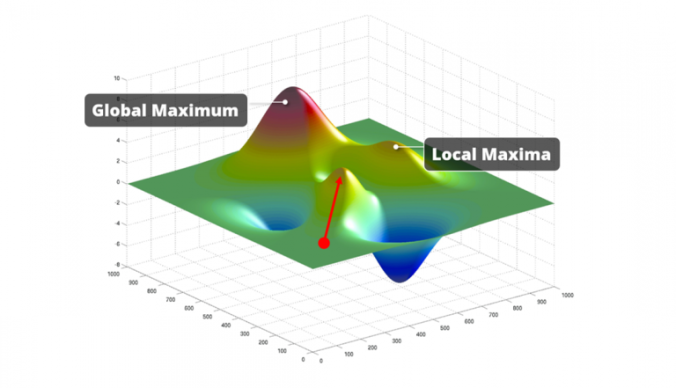
Slow vs. Bad. Anything better out there?
This is not good then, is it? We have one technique which would deliver the optimal result, but is computationally not feasible. This is the brute force approach. But as we have seen, we cannot use it at all on realistic data sets. And we have two heuristics, forward selection and backward elimination, which deliver results much quicker. But unfortunately, they will run into the first local optimum they find. And that means that they most likely will not deliver the optimal result. Don’t give up though – in the next post we will discuss another heuristic which is still feasible even for larger data sets. And it often delivers much better results than forward selection and backward elimination. This heuristic is making use of evolutionary algorithms which will be the topic of the next post.