Supervised learning
Classification, Regression
Lazy Learners / Instance-based Learners
Numerical, Categorical
Fast, Local, Global

One of my quirky videos from the “5 Minutes with Ingo” series. It explains the basic concepts of k-Nearest Neighbors N in 5 minutes. And has unicorns.
Concept
k-Nearest Neighbors is one of the simplest machine learning algorithms. As for many others, human reasoning was the inspiration for this one as well. Whenever something significant happened in your life, you will memorize this experience. You will later use this experience as a guideline about what you expect to happen next.
Consider you see somebody dropping a glass. While the glass falls, you already make the prediction that the glass will break when it hits the ground. But how can you do this? You never have seen THIS glass breaking before, right?
No, indeed not. But you have seen similar glasses or in general similar items dropping to the floor before. And while the situation might not be exactly the same, you still know that a glass dropping from about 5 feet on a concrete floor usually breaks. This gives you a pretty high level of confidence to expect breakage whenever you see a glass fall from that height on a hard floor.
But what about dropping a glass from a foot height onto a soft carpet? Did you experience breaking glasses in such situations as well? No, you did not. We can see that the height matters, so does the hardness of the ground.
This way of reasoning is what a k-Nearest Neighbors algorithm is doing as well. Whenever a new situation occurs, it scans through all past experiences and looks up the k closest experiences. Those experiences (or: data points) are what we call the k nearest neighbors.
If you have a classification task, for example you want to predict if the glass breaks or not, you take the majority vote of all k neighbors. If k=5 and in 3 or more of your most similar experiences the glass broke, you go with the prediction “yes, it will break”.
Let’s now assume that you want to predict the number of pieces a glass will break into. In this case, we want to predict a number which we call “regression”. Now you take the average value of your k neighbors’ numbers of glass pieces as a prediction or score. If k=5 and the numbers of pieces are 1 (did not break), 4, 8, 2, and 10 you will end up with the prediction of 5.
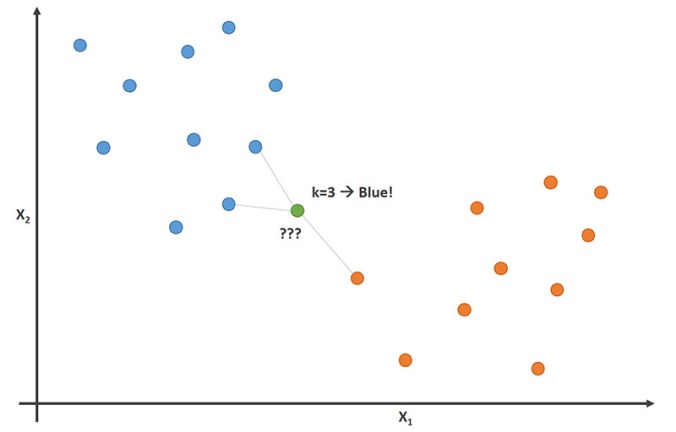
We have blue and orange data points. For a new data point (green), we can determine the most likely class by looking up the classes of the nearest neighbors. Here, the decision would be “blue”, because that is the majority of the neighbors.
Why is this algorithm called “lazy”? Because it does no training at all when you supply the training data. At training time, all it is doing is storing the complete data set but it does not do any calculations at this point. Neither does it try to derive a more compact model from the data which it could use for scoring. Therefore, we call this algorithm lazy.
Theory
We have seen that this algorithm is lazy and during training time all it is doing is to store all the data it gets. All the computation happens during scoring, i.e. when we apply the model on unseen data points. We need to determine which k data points out of our training set are closest to the data point we want to get a prediction for.
Let’s say that our data points look like the following:

We have a table of n rows and m+1 columns where the first m columns are the attributes we use to predict the remaining label column (also known as “target”). For now, let’s also assume that all attribute values x are numerical while the label values for y are categorical, i.e. we have a classification problem.
We can now define a distance function which calculates the distance between data points. Especially, it should find the closest data points from our training data for any new point. The Euclidean distance often is a good choice for such a distance function if the data is numerical. If our new data point has attribute values s1 to sm, we can calculate the distance d(s, xj) between point s to any data point xj by

The k data points with the closest value for this distance become our k neighbors. For a classification task, we now use the most frequent of all values y from our k neighbors. For regression tasks, where y is numerical, we use the average of all values y from our k neighbors.
But what if our attributes are not numerical or consist of numerical and categorical attributes? Then you can use any other distance measure which can handle this type of data. This article discusses some frequent choices.
By the way, K-Nearest Neighbors models with k=1 are the reason why calculating training errors are completely pointless. Can you see why?
Practical Usage
K-Nearest Neighbors, or short: K-NN, should be a standard tool in your toolbox. It is fast, easy to understand even for non-experts, and it is easy to tune it to different kind of predictive problems. But there are some things to consider which we will discuss in the following.
Data Preparation
We have seen that the key part of the algorithm is the definition of a distance measure. A frequent choice is the Euclidean distance. This distance measure treats all data columns in the same way though. It subtracts the values for each dimension before it sums up the squares of those distances. And that means that columns with a wider data range have a larger influence on the distance than columns with a smaller data range.
So, you should normalize the data set so that all columns are roughly on the same scale. There are two common ways of normalization. First, you could bring all values of a column into a range between 0 and 1. Or you could change the values of each column so that the column has a mean 0 with a standard deviation of 1 afterwards. We call this type of normalization z-transformation or standard score.
Tip: Whenever you know that the machine learning algorithm is making use of a distance measure, you should normalize the data. Another famous example would be k-Means clustering.
Parameters to Tune
The most important parameter you need to tune is k, the number of neighbors used to make the class decision. The minimum value is 1 in which case you only look at the closest neighbor for each prediction to make your decision. In theory, you could use a value for k which is as large as your total training set. This would make no sense though, since in this case you would always predict the majority class of the complete training set.
Here is a good way to interpret the meaning behind k. Small numbers indicate “local” models, which can be non-linear and the decision boundary between the classes wiggle a lot. If the number grows, the wiggling gets less until you almost end up with a linear decision boundary.

We see a data set in two dimensions on the left. In general the top right is red and the bottom left is the blue class. But there are also some local groups inside of both areas. Small values for k lead to more wiggly decision boundaries. For larger values the decision boundary becomes smoother, almost linear in this case.
Good values for k depend on the data you have and if the problem is non-linear or not. You should try a couple of values between 1 and about 10% of the size of the training data set size. Then you will see if there is a promising area worth the further optimization of k.
The second parameter you might want to consider is the type of distance function you are using. For numerical values, Euclidean distance is a good choice. You might want to try Manhattan distance which is sometimes used as well. For text analytics, cosine distance can be another good alternative worth trying.
Memory Usage & Runtimes
Please note that all this algorithm is doing is storing the complete training data. So, the memory needs grow linearly with the number of data points you provide for training. Smarter implementations of this algorithm might choose to store the data in a more compact fashion. But in a worst-case scenario you still end up with a lot of memory usage.
For training, the runtime is as good as it gets. The algorithm is doing no calculations at all besides storing the data which is fast.
The runtime for scoring though can be large though which is unusual in the world of machine learning. All calculations happen during model application. Hence, the scoring runtime scales linearly with the number of data columns m and the number of training points n. So, if you need to score fast and the number of training data points is large, then k-Nearest Neighbors is not a good choice.
RapidMiner Processes
You can download RapidMiner here. Then you can download the processes below to build this machine learning model yourself in RapidMiner.
- Train and apply a K-NN model: knn_training_scoring
- Optimize the value for k: knn_optimize_parameter
Please download the Zip-file and extract its content. The result will be an .rmp file which can be loaded into RapidMiner via “File” -> “Import Process…”.
